
# METI:経済産業省の石油統計速報(令和8年1月分)のExcelファイルのパス
https://www.meti.go.jp/statistics/tyo/sekiyuso/result.html
Excel/46KB からダウンロードしたファイルを扱いやすいように加工する。
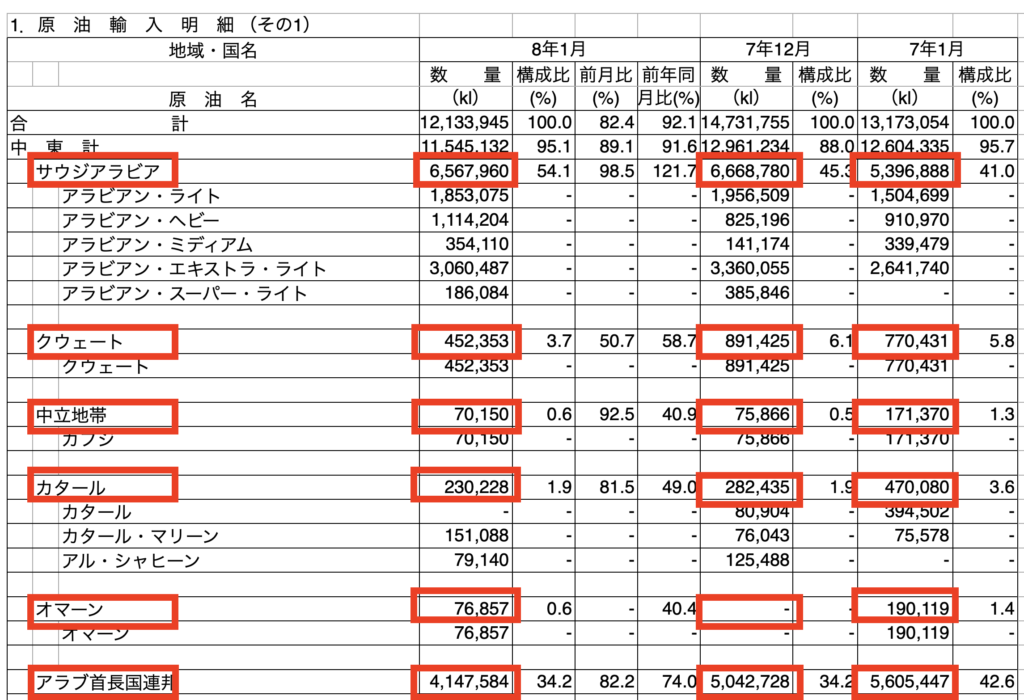
【目標】赤枠で囲った場所だけデータを取り出したい
・原油輸入明細(2頁目) ※下図
・需給概要(5頁目) ※図なし
コメント最小限のコードです。
import pandas as pd
from pathlib import Path
# METI:経済産業省の石油統計速報(令和8年1月分)のExcelファイルのパス
# https://www.meti.go.jp/statistics/tyo/sekiyuso/result.html
EXCEL_PATH = Path(__file__).parent / "h2j581011j.xlsx"
# ====================================================================================
def read_genyu_yunyu_meisai(excel_path: str | Path = EXCEL_PATH) -> pd.DataFrame:
df_excel = pd.read_excel(excel_path, sheet_name='原油輸入明細(2頁目)', header=None)
mask = (
df_excel[1].notna() & (df_excel[1].astype(str).str.strip() != "") &
df_excel[3].notna() & (df_excel[3].astype(str).str.strip() != "")
)
df_filtered = df_excel[mask].copy()
df_result = df_filtered[[1, 3, 7, 9]].copy()
df_result.columns = ["B列", "D列", "H列", "J列"]
return df_result
# ====================================================================================
def read_jyukyu_gaiyo(excel_path: str | Path = EXCEL_PATH) -> pd.DataFrame:
df_excel = pd.read_excel(excel_path, sheet_name='需給概要(5頁目)', header=4)
df_excel = df_excel.rename(columns={'Unnamed: 0': '区分'})
df_excel = df_excel.drop(columns=['Unnamed: 1'])
df_excel = df_excel[df_excel['区分'].notna()]
new_columns = []
for col,tani in zip(df_excel.columns,list(df_excel.iloc[0])):
if col == "区分":
new_columns.append(col)
else:
new_columns.append(f"{col}[{tani}]")
df_excel.columns = new_columns
df_excel = df_excel.drop(index=-0)
df_result = df_excel.copy()
return df_result
# ====================================================================================
if __name__ == "__main__":
if not EXCEL_PATH.exists():
print(f"ファイルが見つかりません: {EXCEL_PATH}")
print("h2j581011j.xlsx をこのスクリプトと同じフォルダに置くか、EXCEL_PATH を変更してください。")
else:
# 原油輸入明細(2頁目)
df = read_genyu_yunyu_meisai()
print(df)
df.to_excel("原油輸入明細.xlsx", index=False)
print("--------------------------------")
# ---------------------------------------------------------------
# 需給概要(5頁目)
df = read_jyukyu_gaiyo()
print(df)
df.to_excel("需給概要.xlsx", index=False)
print("--------------------------------")コメント付きのコードです
# ---------------------------------------------------------------------------
# このスクリプトは経済産業省の石油統計速報Excelから
# 「原油輸入明細」と「需給概要」のシートを読み込み、使いやすい形で返したり
# 別のExcelファイルとして保存したりします。
# ---------------------------------------------------------------------------
import pandas as pd # Excelや表データを扱うためのライブラリ
from pathlib import Path # ファイルパスをOSに依存せず扱うためのライブラリ
# ---------------------------------------------------------------------------
# 定数(プログラム内で変更しない値)
# ---------------------------------------------------------------------------
# METI:経済産業省の石油統計速報(令和8年1月分)のExcelファイルのパス
# https://www.meti.go.jp/statistics/tyo/sekiyuso/result.html
#
# Path(__file__) … このPythonファイル自身のパス
# .parent … その親フォルダ(このスクリプトが入っているフォルダ)
# / "h2j581011j.xlsx" … そのフォルダ内のファイル名を連結
# 結果として「このスクリプトと同じ場所にある h2j581011j.xlsx」を指します。
EXCEL_PATH = Path(__file__).parent / "h2j581011j.xlsx"
# ====================================================================================
# 関数: 原油輸入明細(2頁目)を読み込む
# ====================================================================================
def read_genyu_yunyu_meisai(excel_path: str | Path = EXCEL_PATH) -> pd.DataFrame:
"""
原油輸入明細シートを読み、B列・D列・H列・J列だけを抽出して返します。
空行や必要な列が空の行は除外します。
引数:
excel_path: 読み込むExcelファイルのパス(省略時は EXCEL_PATH を使用)
戻り値:
pandasのDataFrame(表形式のデータ)
"""
# Excelの「原油輸入明細(2頁目)」シートを読み込む
# header=None は「1行目を列名として使わない」という意味(列は 0, 1, 2... の番号で参照)
df_excel = pd.read_excel(excel_path, sheet_name='原油輸入明細(2頁目)', header=None)
# 「マスク」: どの行を残すかを True/False で表した条件
# ・df_excel[1].notna() … 1列目(B列)が欠損(NaN)でない
# ・.astype(str).str.strip() != "" … 文字列に直して空白を除いたとき、空でない
# 1列目と3列目(B列とD列)の両方に値がある行だけを残すための条件です。
mask = (
df_excel[1].notna() & (df_excel[1].astype(str).str.strip() != "") &
df_excel[3].notna() & (df_excel[3].astype(str).str.strip() != "")
)
# 条件に合う行だけを抜き出し、.copy() で別の表としてコピー(元の df_excel を変更しない)
df_filtered = df_excel[mask].copy()
# 必要な列だけを選ぶ(1, 3, 7, 9 は Excel の B, D, H, J 列に相当)
df_result = df_filtered[[1, 3, 7, 9]].copy()
# 列名を分かりやすく「B列」「D列」などに付け直す
df_result.columns = ["B列", "D列", "H列", "J列"]
return df_result
# ====================================================================================
# 関数: 需給概要(5頁目)を読み込む
# ====================================================================================
def read_jyukyu_gaiyo(excel_path: str | Path = EXCEL_PATH) -> pd.DataFrame:
"""
需給概要シートを読み、列名を整理して返します。
5行目をヘッダーとし、6行目の単位を列名に反映します。
引数:
excel_path: 読み込むExcelファイルのパス(省略時は EXCEL_PATH を使用)
戻り値:
pandasのDataFrame(表形式のデータ)
"""
# 「需給概要(5頁目)」シートを読み込む
# header=4 は「0始まりで5行目(4行目)を列名として使う」という意味
df_excel = pd.read_excel(excel_path, sheet_name='需給概要(5頁目)', header=4)
# 列名の整理: pandas が自動で付けた 'Unnamed: 0' を分かりやすい「区分」に変更
df_excel = df_excel.rename(columns={'Unnamed: 0': '区分'})
# 不要な列 'Unnamed: 1' を削除
df_excel = df_excel.drop(columns=['Unnamed: 1'])
# 「区分」が空(NaN)の行は表の区切りや余白なので除外する
df_excel = df_excel[df_excel['区分'].notna()]
# 列名に「単位」を付け足す(Excelの1行目=iloc[0]に単位が書いてある想定)
# zip(列名のリスト, 1行目の値のリスト) で、列ごとに「列名」と「単位」をペアで取り出す
new_columns = []
for col, tani in zip(df_excel.columns, list(df_excel.iloc[0])):
if col == "区分":
new_columns.append(col) # 区分列はそのまま
else:
new_columns.append(f"{col}[{tani}]") # 例: "生産量[万kl]"
df_excel.columns = new_columns
# 単位が入っていた行(先頭行)をデータから削除する(iloc[0] が index 0 の行)
# 注: index=-0 は 0 と同じなので、先頭行が削除される
df_excel = df_excel.drop(index=-0)
df_result = df_excel.copy()
return df_result
# ====================================================================================
# このスクリプトを「直接」実行したときだけ以下が動く
# (他のファイルから import したときは動かない)
# ====================================================================================
if __name__ == "__main__":
# まず Excel ファイルが存在するか確認する
if not EXCEL_PATH.exists():
print(f"ファイルが見つかりません: {EXCEL_PATH}")
print("h2j581011j.xlsx をこのスクリプトと同じフォルダに置くか、EXCEL_PATH を変更してください。")
else:
# --- 原油輸入明細(2頁目)の処理 ---
df = read_genyu_yunyu_meisai()
print(df)
# 読み込んだ表を新しいExcelファイルとして保存する
# index=False は「行番号(0, 1, 2...)をExcelの左端の列に書き出さない」という指定
df.to_excel("原油輸入明細.xlsx", index=False)
print("--------------------------------")
# --- 需給概要(5頁目)の処理 ---
df = read_jyukyu_gaiyo()
print(df)
# 同様に需給概要の表もExcelファイルとして保存する
df.to_excel("需給概要.xlsx", index=False)
print("--------------------------------")結果です。
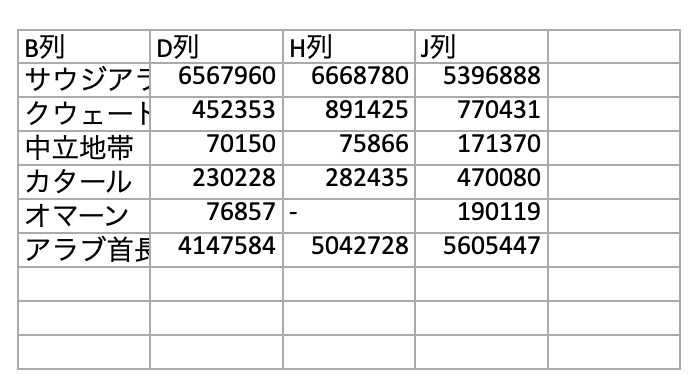
「需給概要(5頁目)」のシートからデータを取り出した結果です。
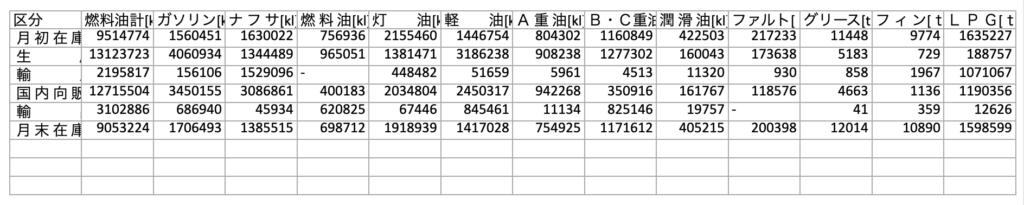
以上です。
